ASR 模型 Playground 使用手册
ASR(Automatic Speech Recognition)Playground 是 Herdsman 为 Sherpa-ONNX 等语音识别模型提供的专用测试界面。允许用户通过上传音频文件或录制麦克风声音,快速验证模型将语音转换为文本的能力。
启动 ASR 模型
- 进入 模型中心 界面
- 在模型列表中寻找带有 ASR 或 语音识别 标签的模型(如
sherpa-onnx 中文非流式 Paraformer Small) - 点击模型卡片上的 立即启动 按钮
- 待模型状态变为 就绪 或 正在运行 后,点击卡片进入 Playground 界面
界面功能详解
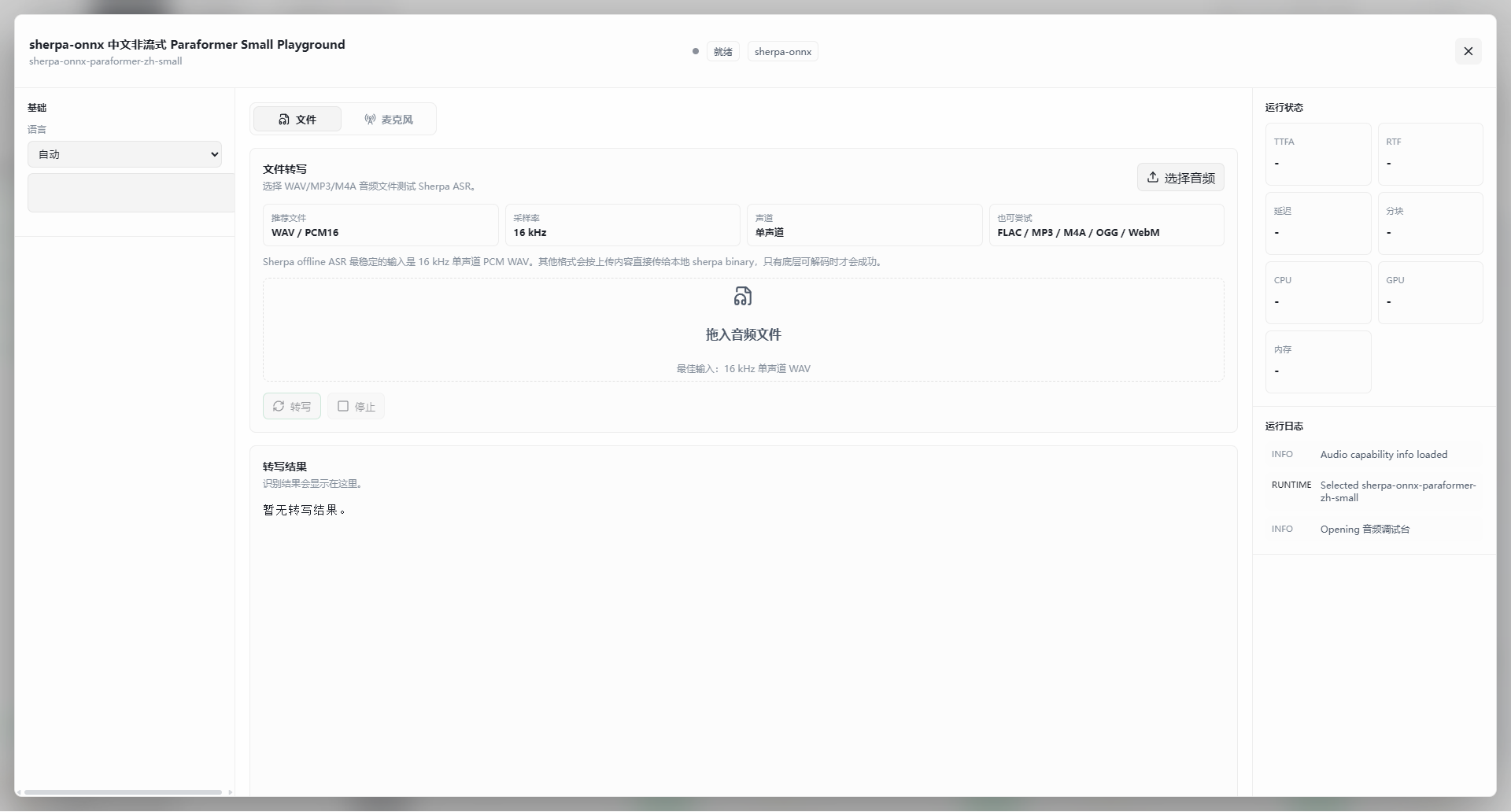
基础设置与输入
- 语言选择(左侧):提供语言下拉菜单(如 自动),可根据音频内容手动指定语言以提高准确率
- 输入模式(顶部 Tab):
- 文件:处理本地音频文件(WAV / MP3 / M4A 等)
- 麦克风:实时录制语音并识别
文件转写参数(核心区域)
- 推荐参数:最稳定的输入为 16 kHz 单声道 PCM WAV
- 兼容格式:也可尝试 FLAC / MP3 / M4A / OGG / WebM(需底层支持解码)
- 操作:拖入文件或点击 选择音频,然后点击 转写
转写成功后的状态说明
当音频文件上传并完成转写后,界面会发生以下变化:
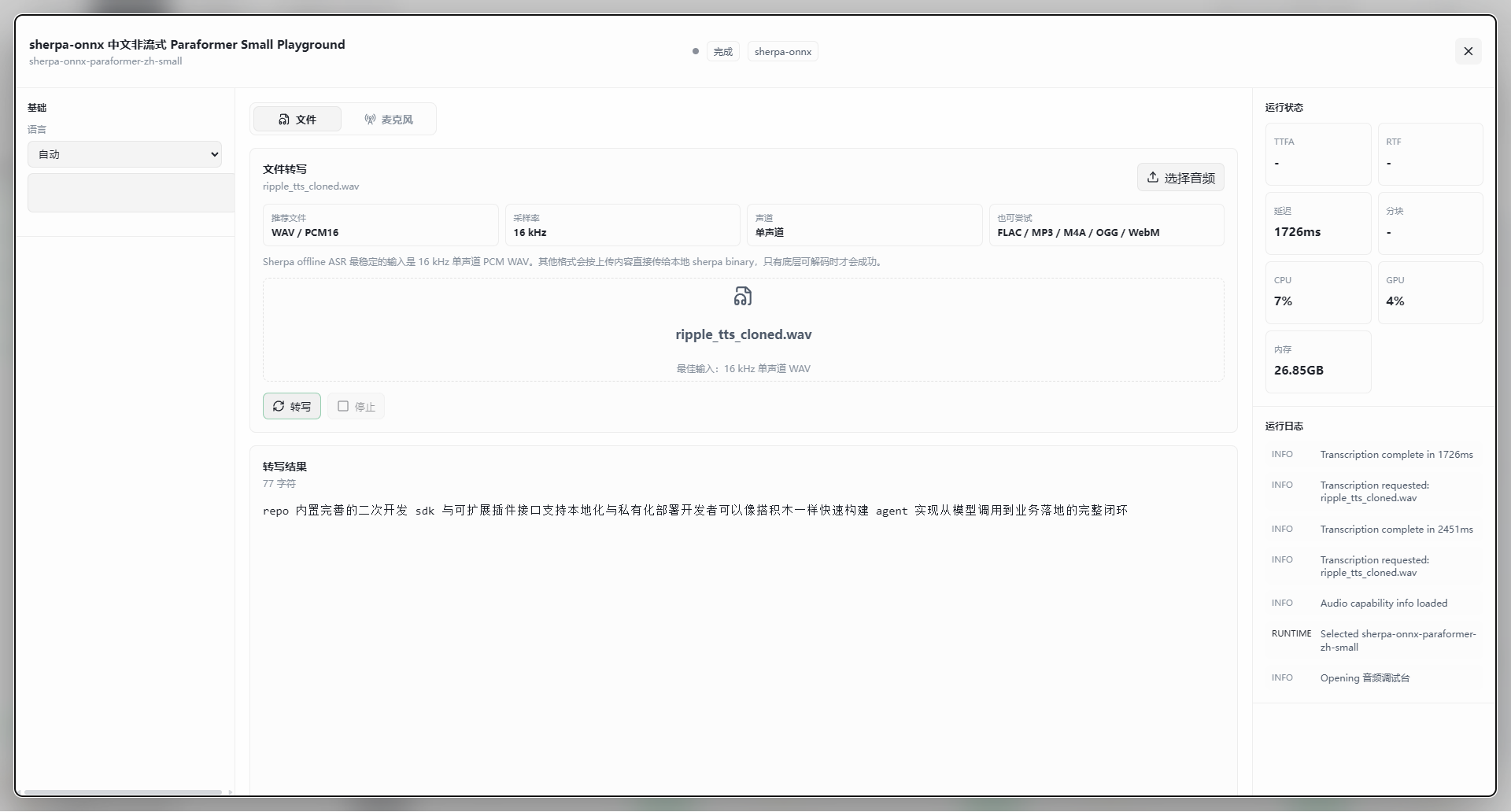
转写结果展示区
- 字符统计:结果标题下方会显示识别出的字符数量(如 77 字符)
- 文本内容:下方文本框展示完整的识别结果
- 示例:"repo 内置完善的二次开发 sdk 与可扩展插件接口支持本地化与私有化部署…"
运行状态监控(右侧边栏)
转写完成后,右侧面板会显示具体的性能数据:
- 延迟:本次转写的具体耗时(如 1726ms,约 1.7 秒)
- 硬件占用:
- CPU:处理时的 CPU 占用率(如 7%)
- GPU:GPU 占用率(如 4%)
- 内存:当前内存使用情况(如 26.85GB)
运行日志(右侧底部)
日志区域记录本次操作的详细信息:
INFO Transcription complete in 1726ms— 确认转写已完成及其耗时INFO Transcription requested: ripple_tts_cloned.wav— 确认正在处理的文件名
常见问题与技巧
Q:为什么上传 MP3 文件后没有结果或报错?
- A:Sherpa offline ASR 对格式要求较高。虽然界面显示"也可尝试 MP3",但如果底层解码器不支持就会失败。最佳实践是先将音频转换为 16kHz 单声道 WAV 格式再上传。
Q:如何判断模型运行快慢?
- A:观察右侧的 延迟 和 RTF(实时率)。如果音频时长 10 秒,延迟显示 1726ms(1.7秒),说明模型处理速度远快于播放速度,性能优秀。