TTS(声音克隆)模型 Playground 使用手册
TTS Playground 是 Herdsman 为语音合成模型(如 Qwen3-TTS)提供的专用测试界面。现以 声音克隆(Voice Clone) 功能进行介绍,允许用户提供一段参考音频,让模型模仿该音频的音色来朗读新的文本。
启动 TTS 模型
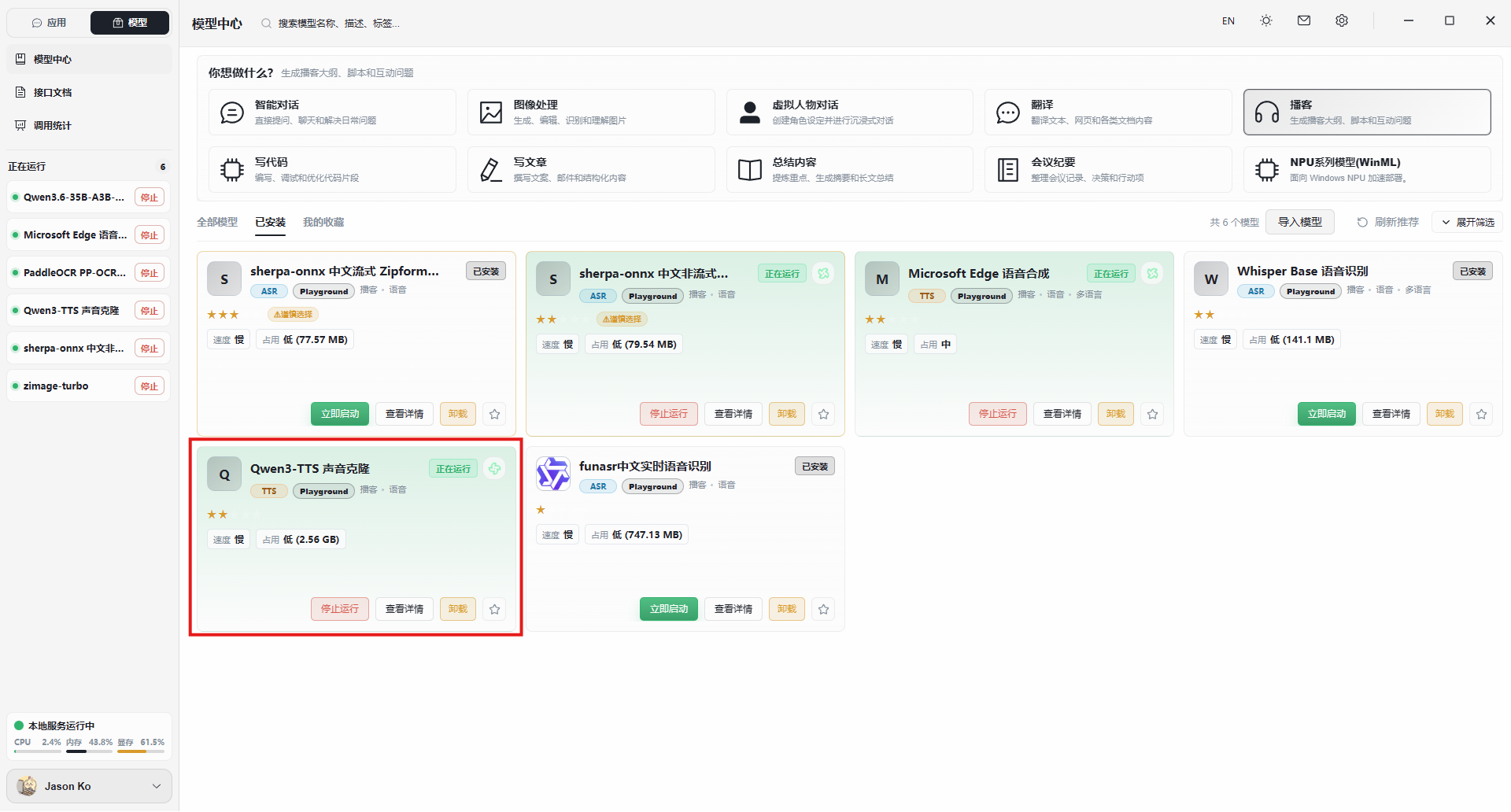
- 进入 模型中心 界面
- 在模型列表中寻找带有 TTS 或 语音合成 标签的模型(如
Qwen3-TTS 声音克隆) - 点击模型卡片上的 立即启动 按钮
- 待模型状态变为 就绪 后,点击卡片进入 Playground 界面
界面功能详解
TTS Playground 界面分为左侧参数区、中间脚本区和右侧监控区。
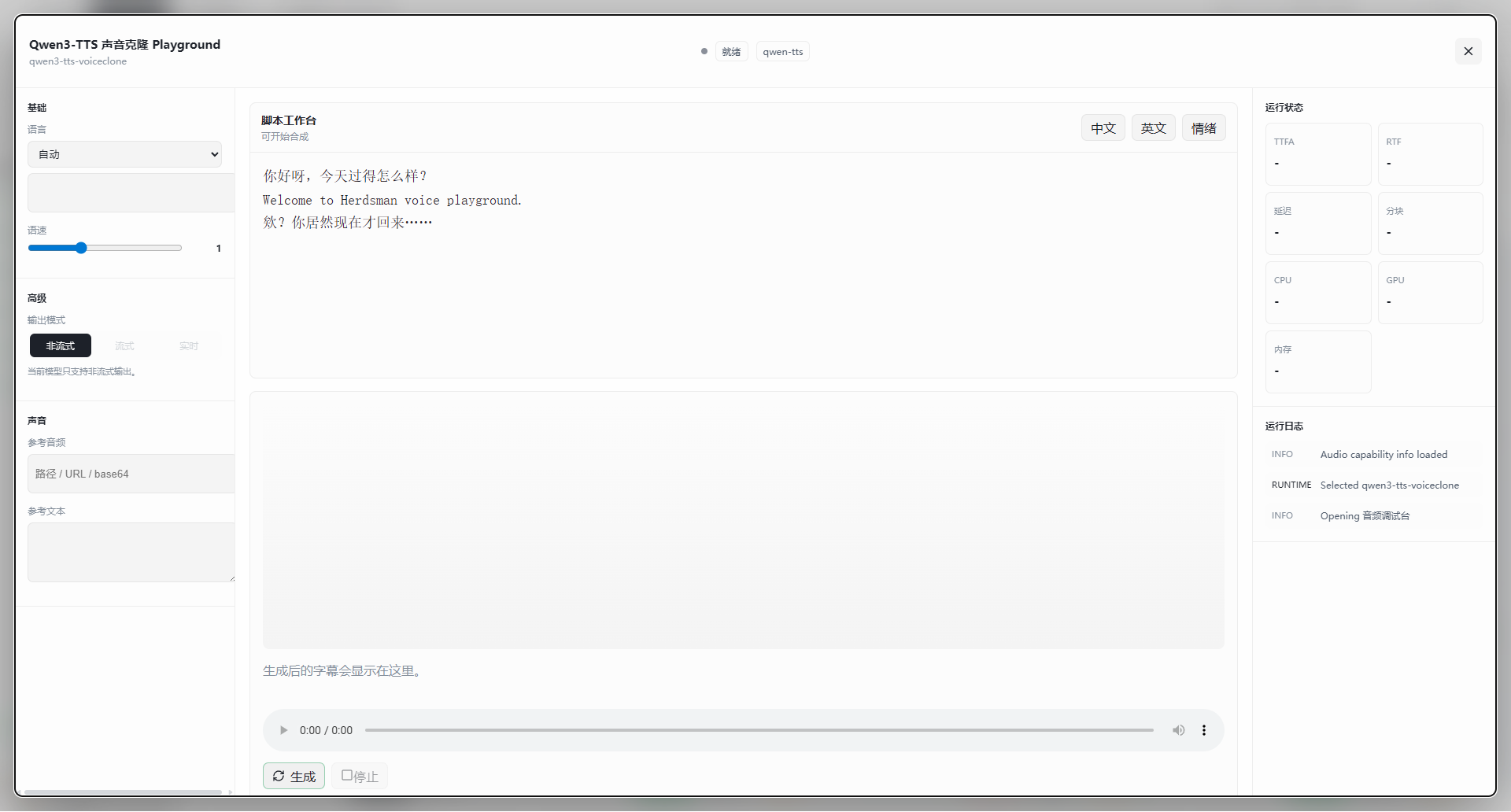
参数设置(左侧边栏)
- 基础设置:
- 语言:下拉选择(如 自动),指定合成文本的语言类型
- 语速:滑动条控制(默认值为 1),向右滑动加快,向左减慢
- 高级设置:
- 输出模式:
- 非流式(截图选中):等待全部音频生成完毕后一次性播放,适合短文本
- 流式/实时:边生成边播放,延迟更低(具体取决于模型能力)
- 输出模式:
- 声音(克隆核心):
- 参考音频:输入想要模仿的声音来源,支持 本地文件路径、网络 URL 或 Base64 编码
- 参考文本:输入参考音频中对应的文字内容。提供准确的参考文本能显著提高克隆的准确度。
脚本工作台(中间主区域)
- 文本输入:
- 在上方文本框输入您希望模型朗读的内容
- 示例:"你好呀,今天过得怎么样?Welcome to Herdsman voice playground."
- 支持中英文混合输入及标点符号停顿
- 功能标签:右上角提供 中文、英文、情绪 标签,用于快速切换输入提示或调整合成风格
- 结果展示:
- 字幕/波形区:生成后的字幕会显示在此处
- 音频播放器:底部提供标准的播放控件(播放/暂停、进度条、音量)
- 控制按钮:
- 生成:点击开始合成语音
- 停止:中断当前的生成任务
运行状态监控(右侧边栏)
- 运行状态:
- TTFA / RTF:首字响应时间与实时率
- 延迟 / 分块:生成延迟及数据块大小
- 硬件占用:CPU、GPU、内存实时监控
- 运行日志:
- 显示模型加载状态(
Selected qwen3-tts-voiceclone)及音频能力初始化信息
- 显示模型加载状态(
快速操作流程(声音克隆模式)
- 准备素材:
- 准备一段清晰的 参考音频(5-10 秒为宜)
- 准备好录音对应的 参考文本(录音里具体说了什么字)
- 设置克隆参数:
- 在左侧 声音 栏的 参考音频 框中填入音频路径或 URL
- 在 参考文本 框中填入对应的文字
- 编写脚本 — 在中间 脚本工作台 输入您想让他说的话
- 调整参数 — 根据需要调整 语速(如设为 1.2 倍速)
- 生成与试听:
- 点击左下角 生成 按钮
- 等待生成完成后,使用底部播放器试听效果。如果音色不像,请检查参考音频是否清晰,或尝试更换参考文本
注意:
- 参考文本的重要性:如果是做声音克隆,务必准确填写参考文本。如果参考文本和参考音频对不上,模型可能无法正确学习音色。
- 格式支持:参考音频通常支持 WAV、MP3 等常见格式,具体取决于模型后端支持。