生成图片
基于 Herdsman 本地部署的文生图、图生图等模型能力实现本地生图修图功能。
本功能对硬件配置要求较高,至少需要 6GB 以上显存才可以使用本功能。
快速开始
- 在对话框中填入图片生成需求,点击 生成图片 按钮
-
等待一段时间,下方进度条显示生成进度
电脑配置和需求复杂程度不同,时间有长有短,请耐心等待。
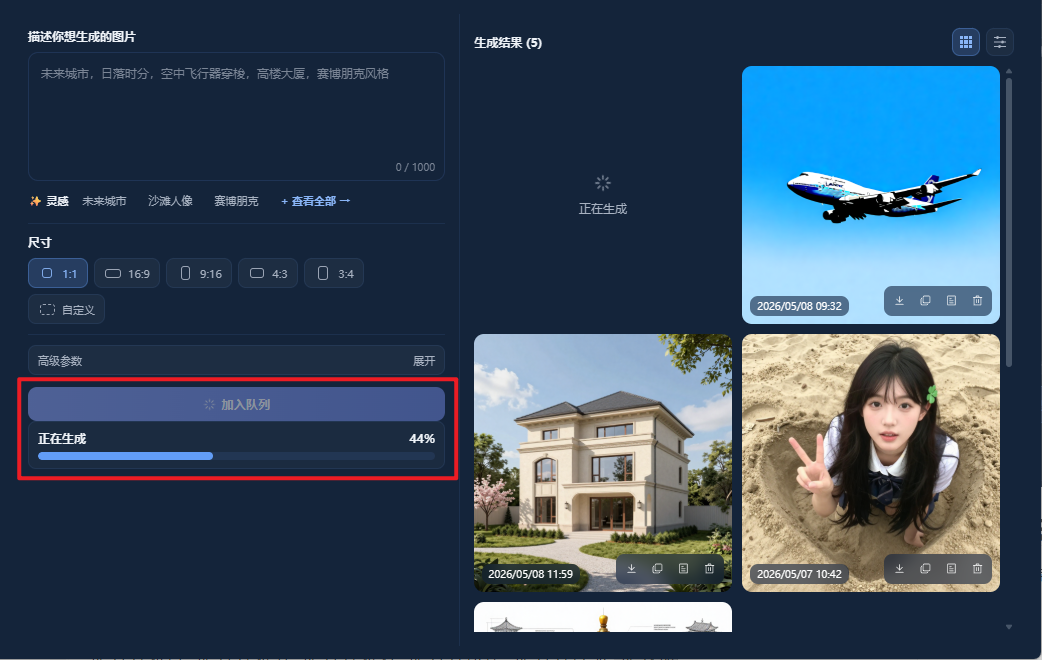
- 图片生成后,在右侧 生成结果 下可以查看结果图
参数设置
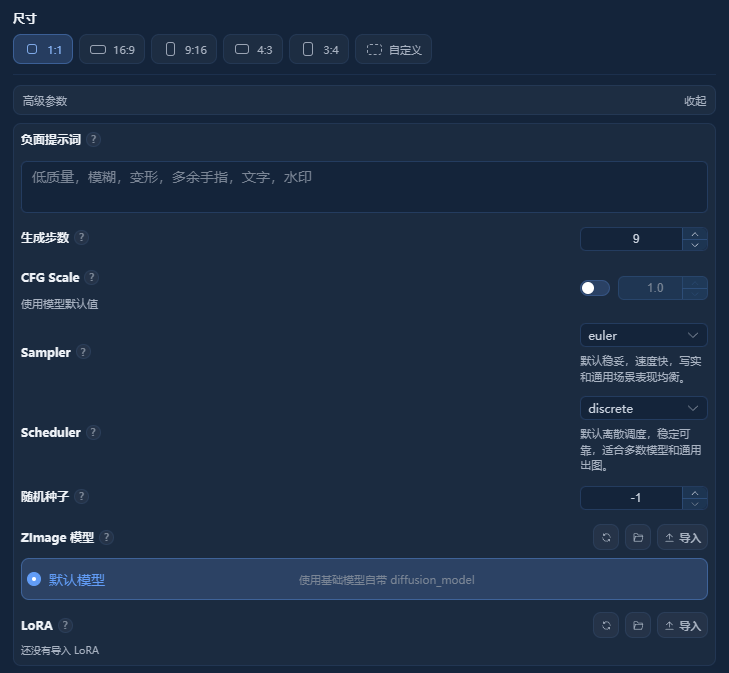
1. 尺寸 (Size)
- 控制输出图像的宽高比例和像素大小
- 可选预设:1:1、16:9、9:16、3:2、4:3,或自定义分辨率
- 影响画面构图与细节密度——高分辨率更清晰但耗时更长
2. 负面提示词 (Negative Prompt)
- 告诉模型"不要生成什么"
- 示例:"低质量,模糊,变形,多余手指,文字,水印" → 用于避免常见缺陷
- 对提升画面干净度、人体结构准确性非常关键
3. 生成步数 (Steps)
- 控制扩散过程迭代次数,值越高画质越精细,但速度越慢
- 默认设为
9 - 注意:不是越多越好!超过一定步数后提升边际递减
4. CFG Scale (Classifier-Free Guidance)
- 控制提示词对生成的约束强度
- 值越高 → 越贴近你的描述,但可能导致过饱和或不自然;值越低 → 更自由、柔和
- 默认设为
1.0
5. Sampler (采样器)
- 决定图像是如何从噪声逐步"画"出来的算法
- 当前选的是
euler— 一种经典、快速、稳定的采样方法,适合写实风格 - 其他选项如 DPM++、DDIM、UniPC 等各有优劣势(速度/质量/稳定性)
6. Scheduler (调度器)
- 控制噪声衰减节奏,影响生成过程中的平滑度和细节表现
- 当前选的是
discrete— 离散式调度,稳定可靠,适合多数模型 - 如使用连续型(如 karras、exponential)可提升边缘锐利度或纹理质感
7. 随机种子 (Seed)
- 控制生成结果的"随机性",相同 seed + 其他参数一致 → 输出几乎完全一样
-1表示每次自动生成新种子(即随机结果)- 若想复现某张图,需记录并固定该种子值
8. ZImage 模型 / LoRA
- ZImage 模型:选择主生成模型(如 SDXL、SD1.5、Flux 等),当前选"默认模型"
- LoRA:轻量级微调模型,用于特定风格、角色、服饰等增强
- "还没有导入 LoRA" → 说明尚未加载任何扩展模型
图片历史
图片历史支持查看生图历史提示词,方便多次调整和存储优质提示词。
- 点击历史可查看对应生图提示词
常见问题
Q:为什么我的电脑无法进行生图操作?
- 请先确认是否安装了本地文生图模型,如果没有安装请先安装后再尝试。
- 如果安装好模型后仍无法使用,可能是因为本功能对硬件要求配置较高,建议查看本机硬件配置是否合适后再使用。
- 如果配置支持,仍无法使用,建议您排查是否模型启动过多?对性能占用太高而导致任务无法执行?如果是建议您先关停不需要使用的模型后再使用(具体操作:点击切换模型页 → 查看正在运行中的模型,关停不需要使用的模型)。
Q:为什么生成的图片和我想象中的不一样?
主要有 4 个原因:
- 提示词太模糊 — 模型只能按字面理解,不会读心。"一只猫" → 什么猫?什么姿势?什么环境?写得越具体越接近。
- 模型有默认值 — 你没说的参数(构图、光线、风格),模型会自己填——但它的默认值大概率和你脑中的不一样。
- 模型"认识"但不"理解" — 它知道手有五指,但不知道手指怎么摆才自然。复杂空间关系、透视、文字经常出错——这是底层能力边界。
- 潜台词没写出来 — "孤独氛围""戏剧感""温暖"这类情绪词必须显式写,模型读不到你的潜台词。
Q:为什么生成文字内容会乱码?
因为文生图模型其实 不认字——它只是把文字当成"有特殊形状的图块"来画。
打个比方: 你让一个完全不懂中文的外国人照着写"你好"。他看这些字就像看一堆奇怪的线条,只能照着描——描出来的大概率歪歪扭扭、缺胳膊少腿。
怎么改善?
- 尽量少在画面里放文字,模型并不擅长"画字"
- 如果一定要有,尽量用最简单的字体、最少的字数
- 后期用 PS 或其他工具手动加上去,比让模型生成更靠谱