什么是大模型?
大模型 全称叫「大语言模型」,可以理解成:
一个超级聪明的 AI 大脑,读过差不多整个互联网的内容,能和你正常聊天、写文章、回答问题。
举个具体的例子
你使用的豆包与他对话——背后就是一个大模型在工作。你打字提问,它理解你的意思,然后组织语言回答你。这就是大模型在干活。
简单比喻
想象有一个超级学霸,他读完了:
- 全网所有书籍(几千万本)
- 所有维基百科
- 无数论坛、新闻、论文
- 各种代码仓库
他记性特别好,但不是死记硬背,而是理解了 语言和知识的规律。你想问什么,他都能试着回答。这个"学霸"就是大模型。
它跟普通程序有什么区别?
关键是:你和它说人话就行,不用学编程,不用点菜单。
它都能干啥?
- 聊天问答 — 就像你现在这样
- 写作 — 写文章、写邮件、写文案
- 编程 — 写代码、修 bug
- 翻译 — 中英文互译
- 总结 — 把长文章读一遍,给你讲重点
- 脑暴 — 帮你出主意、想点子
- 润色 — 把你写的话改得更顺
也不是万能的
- 可能瞎编 — 有时会一本正经地胡说八道(这叫"幻觉")
- 知识有截止日期 — 不知道最新发生的事(除非去搜索)
- 没有真正的意识 — 它只是根据概率预测最合适的回答,不是真的在"想"
一句话总结:大模型就是一个读过海量知识、能和你像正常人一样聊天的 AI 大脑。
如何使用大模型
最基础的方式:对话界面
使用大模型最简单的方式就是 直接打字聊天。
用户只需要打开一个对话窗口(如 Herdsman、FlowyAIPC、豆包等的聊天界面),像跟人说话一样输入文字,模型就会给出回复。这种方式的门槛几乎为零。
- 不需要学习任何操作指令
- 不需要编程知识
- 不需要记住复杂的菜单或按钮
使用流程: 输入问题 → 模型理解 → 输出答案
提示词技巧:如何获得更好的回答
用户与模型交互的核心方式是 文字对话,但更详细更准确的指令会让大模型的执行和回复更准确和优质。
以下是一些基本原则:
进阶版交互
大模型只能接收 文字 输入,也只能输出 文字。像阅读文件、打开浏览器等操作是依赖 大模型工程化程序 的 AI 助手(如 FlowyAIPC、Herdsman)才能实现。
文件交互
除了文字对话,部分 AI 助手(如 Herdsman 和 FlowyAIPC)还支持 文件交互:
- 上传文档 → 让模型总结、翻译、提取信息
- 上传图片 → 让模型识别图片内容、提取文字
- 上传表格 → 让模型分析数据、生成图表
操作方式通常很简单:在对话窗口中找到文件上传按钮,或将文件直接拖入聊天区域即可。
输出文件
反过来,AI 助手也可以直接生成文件供用户下载使用:
- Word 文档(.docx) — 报告、合同、简历、信函
- Excel 表格(.xlsx) — 数据报表、清单、统计表
- PowerPoint 演示文稿(.pptx) — 幻灯片、汇报材料
- PDF 文件 — 正式文档、归档材料
用户只需在对话中提出需求,模型便会生成对应的文件。
实际使用场景举例
以下是一些常见场景及对应的对话方式:
写邮件: 帮我写一封邀请函,邀请客户参加下周五的产品发布会,语气要热情但专业。
读文档: 这份 PDF 有 50 页,帮我总结出三个核心观点。
学知识: 用最简单的比喻解释什么是区块链。
改内容: 这段话帮我改写成领导讲话的风格。
出主意: 我下周要做个团建,帮我想五个有趣的活动方案。
使用注意事项
- 核对重要信息 — 对于数字、日期、引用等关键内容,建议人工确认
- 隐私保护 — 不要在对话中输入密码、身份证号等敏感信息(尤其在在线模式下)
- 尝试调整 — 如果回答不满意,可以换一种方式重新提问,通常会有更好的效果
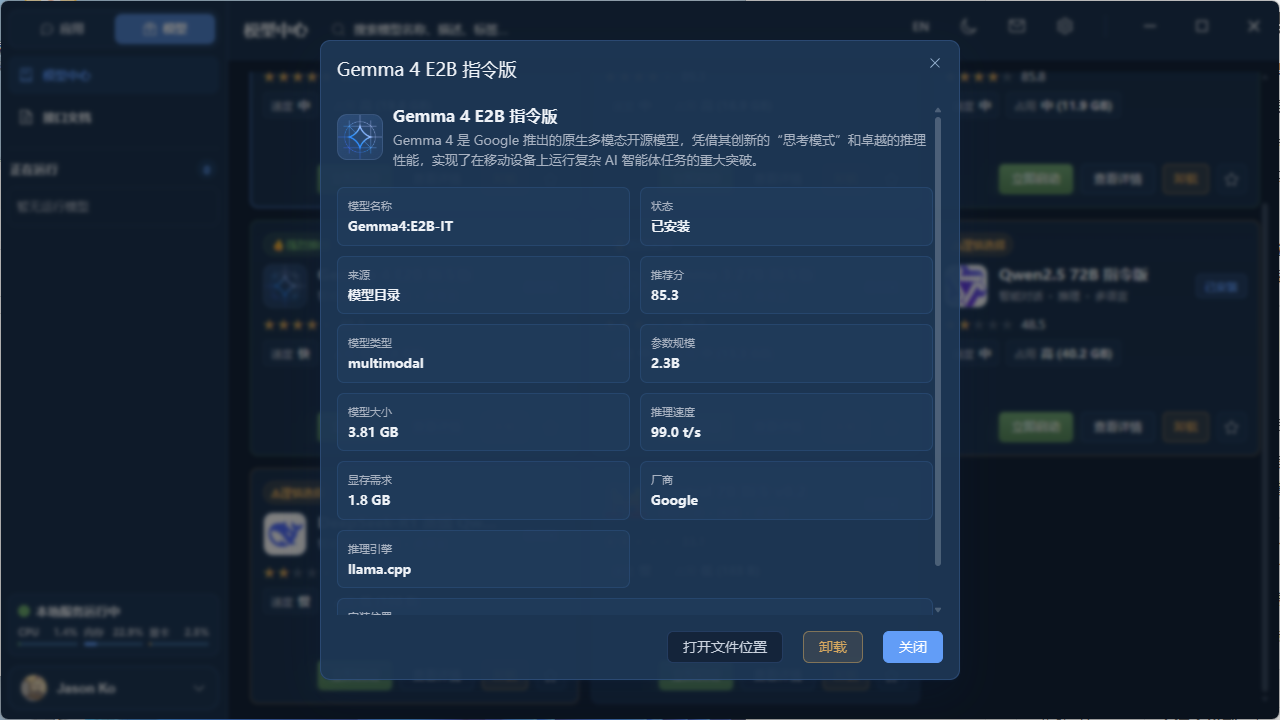
模型名字里的秘密——以 Gemma 4 E2B 为例
一个模型的名字通常包含三层信息:谁做的 + 哪个版本 + 有多大。
Gemma — 模型来自谷歌(Google)的开源系列。就像手机有苹果、华为、小米,模型也有谷歌、Meta(Llama)、深度求索(DeepSeek)等不同"厂家"。各有各的技术路线,各有各的特点。
4 — 版本号。说明这是第四代。每一代新版本通常比上一代更聪明、更准确。就像 iPhone 14 比 iPhone 13 更强。
E2B — 这个后缀说明了模型的规格。拆开看:
E = Edge(端侧),表示这是面向端侧部署的版本——专门为在笔记本、台式机、边缘 AI 盒子等本地资源有限的设备上运行而优化 2B = 2 Billion ≈ 20 亿参数,代表模型的大小
当然它也可能搭配更大的尺寸即将发布。你先不用纠结死记这个名称的含义,关键是理解:名字里每个部分都透露了信息。
参数"2B"到底意味着什么?
2B = 20 亿参数。
参数是模型"脑细胞"的数量。可以把参数想象成知识连接的密度:
所以 Gemma 4 E2B 是一个轻量模型——它不一定能回答最刁钻的问题,但它在普通电脑上跑得飞快,适合日常使用。
为什么会有这么多不同的模型?
你下载了 Gemma,其他人可能用 DeepSeek 或 Qwen。这是为什么呢?
原因可以归结为三点:
- 不同公司 — 谷歌、Meta、深度求索、阿里……每家公司都训练自己的模型
- 不同大小 — 同样一家公司的模型,会有 2B、7B、70B 等不同版本,满足不同设备需求
- 不同侧重点 — 有的擅长中文、有的擅长编程、有的轻便快速
你不需要记这些。你只需要知道:选择更多了,可以根据自己的设备和使用场景挑选最合适的那一个。
Edge——后缀里的"E"代表什么
Gemma 4 E2B 中的 "E"(Edge) 表示这是一款 端侧(Edge)部署版本 ——专门为在本地、资源有限的硬件(笔记本、台式机、边缘 AI 盒子等)上直接运行而设计,而不是部署在大型云端服务器上。
传统云端大模型像一台功能强大但耗电惊人的大型机,而端侧模型更像一台紧凑、节能的小家电:
- 体积更小 — 模型文件、内存占用、磁盘消耗都更精简
- 硬件门槛低 — 普通消费级电脑就能跑,不一定需要专业级显卡
- 本地响应更快 — 无需走网络,延迟更低、更稳定
- 隐私默认安全 — 推理完全在本地完成,输入数据不出你的设备
简单来说,"E" 后缀代表模型牺牲了一部分峰值能力,换来了"在哪里都能跑"的便利——这正是 Herdsman 想要实现的使用场景。
多模态——模型能"看懂"图片吗?
Gemma 4 E2B 具备 多模态 能力。
单模态 = 只能处理文字(你打字它回字) 多模态 = 不仅能看文字,还能"看懂"图片
比如在 FlowyAIPC 中,如果上传一张菜单的照片,你可以问"这里面哪个菜最辣?",模型会看图片然后告诉你答案——这就是多模态的实际应用。
文生图、语音识别(ASR)——这些不是同一个模型
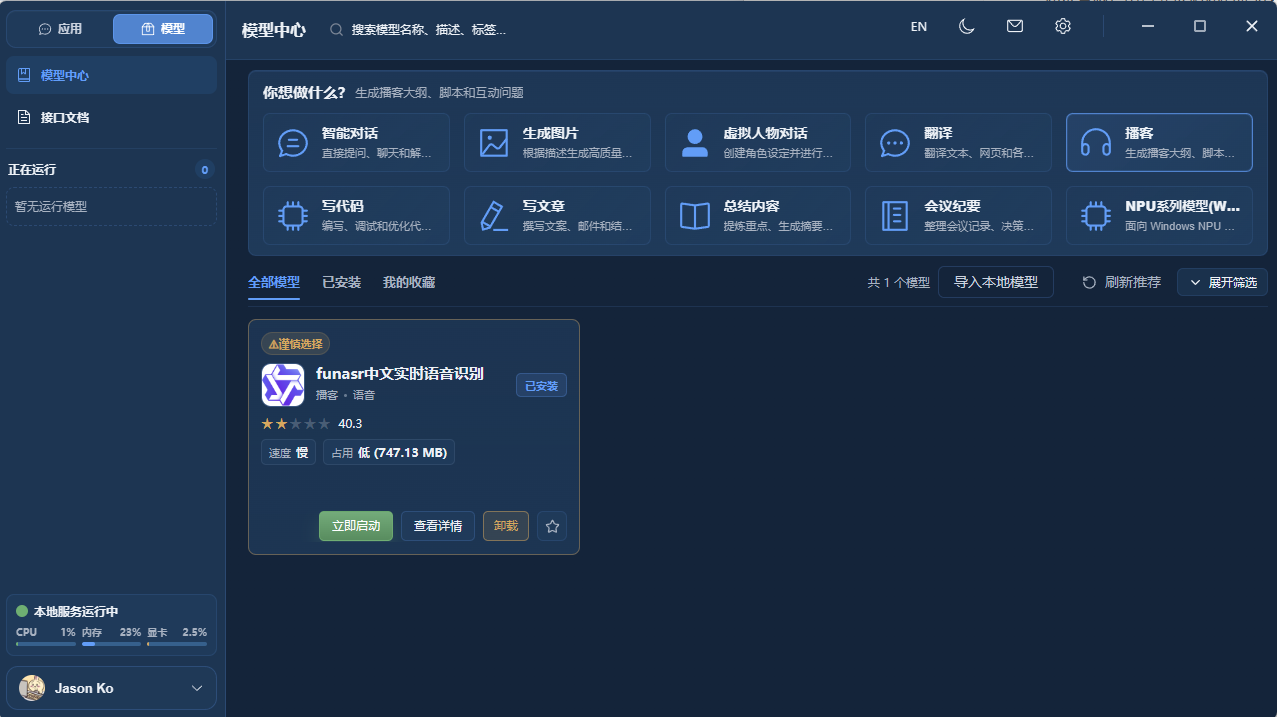
有了 Gemma 4 E2B 这样的大模型,就可以完成上面说的对话、图文理解。
但如果想 生成一张图片,或者 把语音转成文字,则需要用到 其他类型的 AI 模型:
在 Herdsman 中,不同能力模型都被整合好了,可以按照自己的实际需求点击一键下载即可使用。下图中就是 语音转文字 模型。